谷歌 Cloud 全球宕机超 3 小时, 官方确认 API 管理失误导致
- 2025-06-27 02:23:26
- 458
IT之家6月14日消息,谷歌表示于北京时间6月14日22点49分到6月15日凌晨1点49分,发生的GoogleCloud大规模宕机事件源于API管理问题,持续超过三小时,影响全球数百万用户。
IT之家援引博文介绍,谷歌表示在本次大规模宕机事件中,包括Gmail、GoogleCalendar、GoogleDocs、GoogleDrive和GoogleMeet等核心工具无法正常使用。
谷歌表示,问题的根源在于API管理平台因无效数据而失效,且由于缺乏有效的测试和错误处理机制,未能及时发现并修复问题。
此次宕机不仅冲击Google自身服务,还波及众多依赖GoogleCloud的第三方平台,包括Spotify、Discord、Snapchat、NPM和FirebaseStudio等。
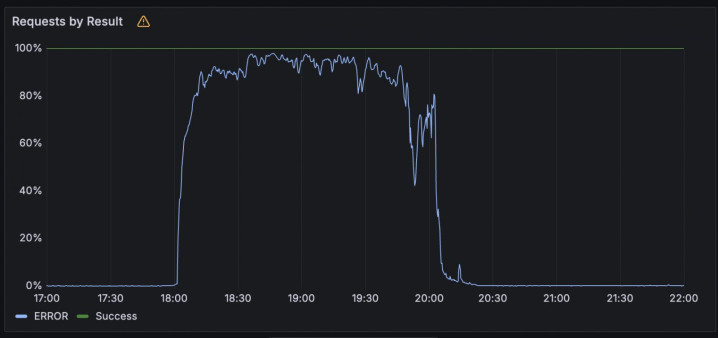
Cloudflare部分服务也因依赖WorkersKV键值存储系统而中断。Google解释,问题源于API管理系统的一次无效自动化配额更新,导致外部API请求被拒绝。尽管大多数地区在两小时内恢复,但us-central1区域的配额策略数据库超载,恢复时间更长。
Cloudflare在事后分析中指出,此次宕机并非安全事件引发,也未造成数据丢失。问题出在WorkersKV服务依赖的底层存储基础设施,而该基础设施部分由第三方云服务商提供(未明确指名,但确认与GoogleCloud相关)。
为避免类似事件,Cloudflare计划将KV核心存储迁移至自有的R2对象存储系统,以减少对外部服务的依赖。
- 上一篇:进一步关心海洋认识海洋经略海洋
- 下一篇:黄圣依白月光的杀伤力
